Python Interface
envpool.make
The main interface is envpool.make where we can provide a task id and some
other arguments (as specified below) to generate different configuration of
batched environments:
task_id (str): task id, useenvpool.list_all_envs()to see all support tasks;env_type (str): generate with the Gymnasium-compatible wrapper ordm_env.Environmentinterface, available options aredm,gym, andgymnasium;num_envs (int): how many envs are in the envpool, default to1;batch_size (int): async configuration, see the last section, default tonum_envs;num_threads (int): the maximum thread number for executing the actualenv.step, default tobatch_size;seed (int | Sequence[int]): set seed over all environments. If an int is provided, the i-th environment seed will be set with i+seed. If a sequence is provided, it must contain exactly one seed per environment. The default is42;max_episode_steps (int): set the max steps in one episode. This value is env-specific (27000 steps or 27000 * 4 = 108000 frames in Atari for example);max_num_players (int): the maximum number of player in one env, useful in multi-agent env. In single agent environment, it is always1;thread_affinity_offset (int): the start id of binding thread.-1means not to use thread affinity in thread pool, and this is the default behavior;reward_threshold (float): the reward threshold for solving this environment; this option comes fromenv.spec.reward_thresholdin the Gymnasium API, while some environments may not have such an option;gym_reset_return_info (bool): a deprecated compatibility flag kept in the config schema. EnvPool’sgymwrapper follows Gymnasium reset semantics and always returns(obs, info); passingFalseraisesValueError;render_mode (str | None): render behavior exposed by the Python wrapper. Available options areNone(default),"rgb_array", and"human";render_env_id (int): default env id used byenv.render()whenenv_idsis omitted, default to0;render_width/render_height: fixed output size forrender(). If omitted, the environment-specific default render size is used;render_camera_id (int): default camera id used byrender(), default to-1;from_pixels (bool): for MuJoCo tasks, expose native C++ render-backed pixel observations through the normal observation API instead of the environment’s state observations;other configurations such as
img_height/img_width/stack_num/frame_skip/noop_maxin Atari env,reward_metric/lmp_save_dirin ViZDoom env, please refer to the corresponding pages.
The observation space and action space of resulted environment describe a
single environment’s space, but each time the observation/action’s first
dimension is always equal to num_envs
(sync mode) or equal to batch_size (async mode).
For Gymnasium compatibility, the Gymnasium wrapper also exposes
num_envs, is_vector_env, single_observation_space, and
single_action_space for vector-aware wrappers such as Gymnasium’s vector
NormalizeObservation. EnvPool keeps observation_space and
action_space as the single-environment spaces for backward compatibility.
envpool.make_gym, envpool.make_dm, and envpool.make_gymnasium are
shortcuts for envpool.make(..., env_type="gym" | "dm" | "gymnasium"),
respectively.
envpool.make_spec
If you don’t want to create a fake environment, meanwhile want to get the
observation / action space, envpool.make_spec would help. The argument is
the same as envpool.make, and you can use
spec.observation_spacegym’s observation space;spec.action_spacegym’s action space;spec.observation_spec()dm_env’s observation spec;spec.action_spec()dm_env’s action spec;
to get the desired spec.
Extended API
We mainly change two functions’ semantic: reset and step, meanwhile
add another two primitives send and recv:
reset(id: Union[np.ndarray, None]) -> TimeStep: reset the givenidenvs and return the corresponding observation;async_reset() -> None: it only sends the reset command to the executor and return nothing;send(action: Any, env_id: Optional[np.ndarray] = None) -> None: send the action with corresponding env ids to executor (thread pool).actioncan be numpy array (single observation) or a dict (multiple observations);recv() -> Union[TimeStep, Tuple[Any, np.ndarray, np.ndarray, np.ndarray]]: receive the finished env ids (intimestep.observation.obs.env_id(dm) orinfo["env_id"](gym / gymnasium)) and corresponding result from executor;step(action: Any, env_id: Optional[np.ndarray] = None) -> Union[TimeStep, Tuple[Any, np.ndarray, np.ndarray, Any]]: given an action, an env (maybe with player) id list wherelen(action) == len(env_id), the envpool will put these requests into a thread pool; then, if it reaches certain conditions (explain later), it will return the env id listenv_idand result that finished stepping.
In short, step(action, env_id) == send(action, env_id); return recv()
Rendering
EnvPool exposes rendering through the Python wrapper. When creating an env with
render_mode="rgb_array", calling render() returns a batch of RGB frames
with shape (B, H, W, 3) and data type uint8. Even a single env render keeps
the batch dimension, so env.render() returns (1, H, W, 3) by default.
render_mode="human" uses the same renderer, but displays the frame through
OpenCV in Python and returns None. Human mode currently supports only a
single env id per call.
The render API is:
render(env_ids: int | Sequence[int] | None = None, camera_id: int | None = None)
If env_ids is omitted, EnvPool renders render_env_id. The output size
is fixed when the env is created via render_width / render_height;
render() itself does not take a runtime resize argument.
Example:
env = envpool.make(
"Ant-v5",
env_type="gymnasium",
num_envs=4,
render_mode="rgb_array",
render_width=480,
render_height=480,
)
env.reset()
frames = env.render(env_ids=[0, 2])
assert frames.shape == (2, 480, 480, 3)
viewer = envpool.make(
"WalkerWalk-v1",
env_type="gymnasium",
num_envs=1,
render_mode="human",
render_env_id=0,
)
viewer.reset()
viewer.render()
Representative first-frame compares for EnvPool families that support rendering. In each panel, EnvPool is on the left and the reference output is on the right. For Box2D, Classic Control, MiniGrid, MuJoCo, Gymnasium-Robotics, and MyoSuite, the reference is the upstream Python renderer. For Atari, Procgen, and VizDoom, the reference is the exact in-tree render oracle used by the test suite. Google Research Football is intentionally excluded here because its render API is unsupported.

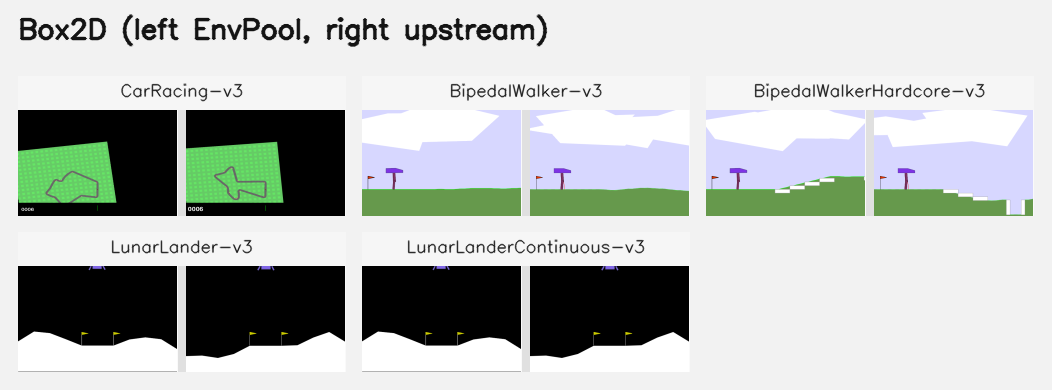


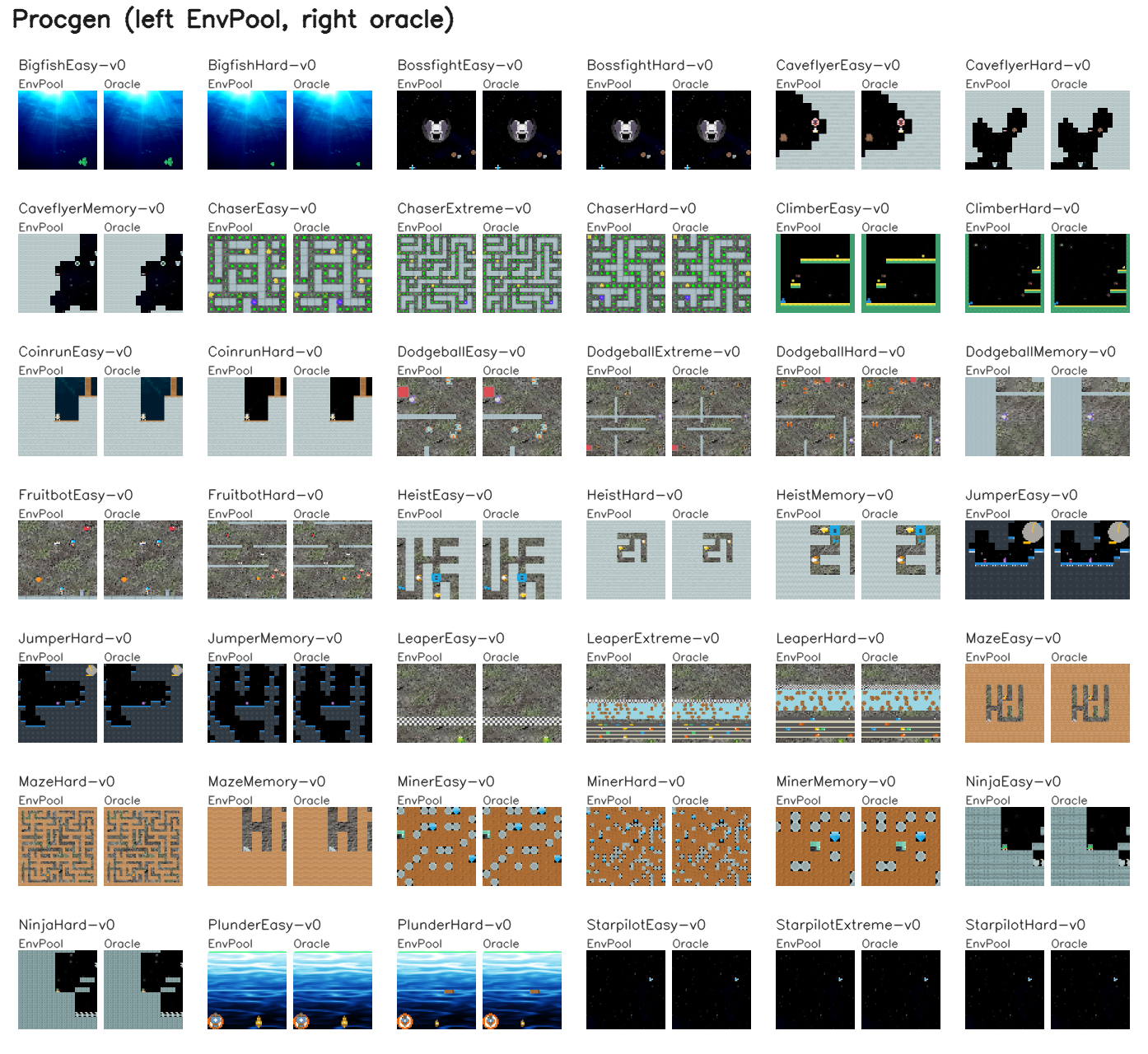

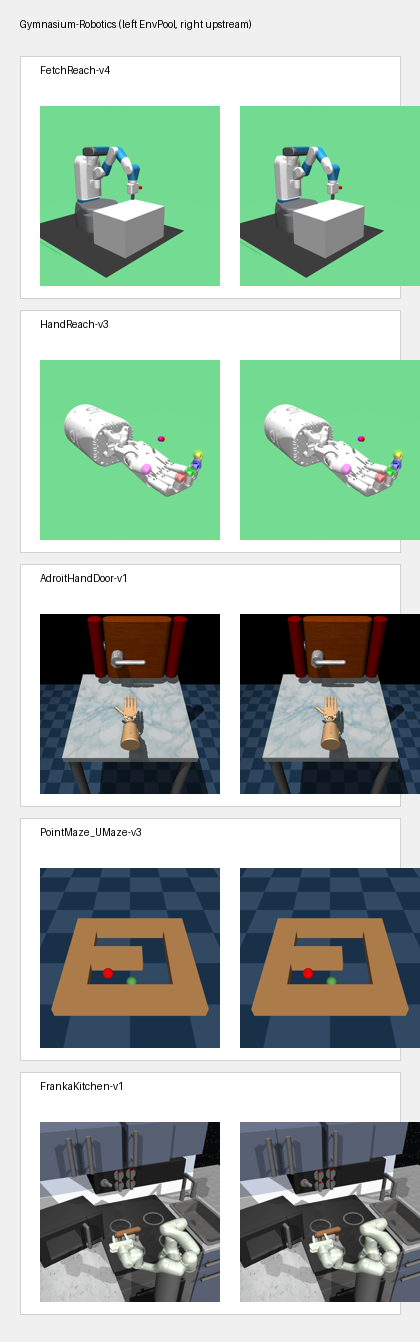




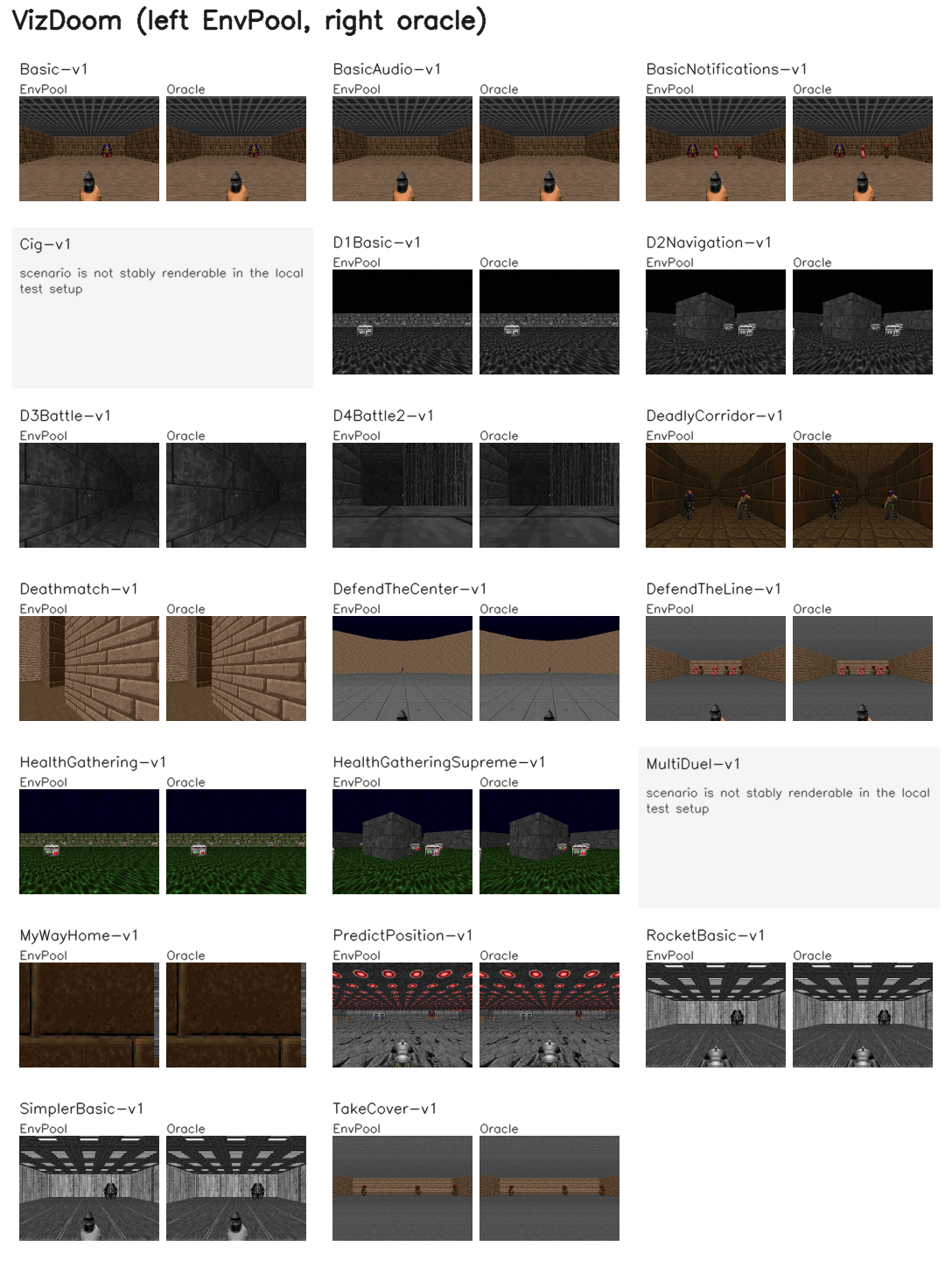
Pixel Observations
When from_pixels=True is passed to envpool.make / make_dm /
make_gym / make_gymnasium for MuJoCo tasks, EnvPool uses a native C++
render path to populate the public observation API.
For Gym and Gymnasium wrappers, the returned observation becomes a uint8
tensor in channel-first layout: (B, 3, H, W) when frame_stack == 1 and
(B, 3 * frame_stack, H, W) otherwise. The info dictionary remains
unchanged.
For the dm_env wrapper, the timestep observation keeps the usual info fields
such as env_id while replacing the state observation payload with a
pixels field.
frame_stack is applied on the channel dimension, so the observation surface
matches the usual PyTorch BCHW convention directly. If render_width /
render_height are omitted, EnvPool defaults both to 84 so the
resulting observation spec is fully defined up front.
Action Input Format
EnvPool supports two action formats in send and step:
(action: np.ndarray, env_id: Optional[np.ndarray] = None): for single-array action input;action: Dict[str, Any]: for multi key-value action input, or in multi-player env some player’s action space are not the same.
For example, in Atari games, we can use the following action formats:
envpool.send(np.ones(batch_size))
envpool.send(np.ones(batch_size), env_id=np.arange(batch_size))
envpool.send({
# note: please be careful with dtype here
"action": np.ones(batch_size, dtype=np.int32),
"env_id": np.arange(batch_size, dtype=np.int32),
})
For the first and second cases, use env.step(action, env_id); for the
third case, use env.step(action) where action is a dictionary.
Data Output Format
function |
gym / gymnasium |
dm |
|---|---|---|
reset |
|
env_id -> TimeStep(FIRST, obs|info|env_id, rew=0, discount or 1) |
step |
|
TimeStep(StepType, obs|info|env_id, rew, discount or 1 - done) |
Note: gym.reset() doesn’t support async step setting because it cannot get
env_id from reset() function, so it’s better to use low-level APIs such
as send and recv.
Batch Size
In asynchronous setting, batch_size means when the finished stepping
thread number >= batch_size, we return the result. The figure below
demonstrate this idea (waitnum is the same as batch_size):
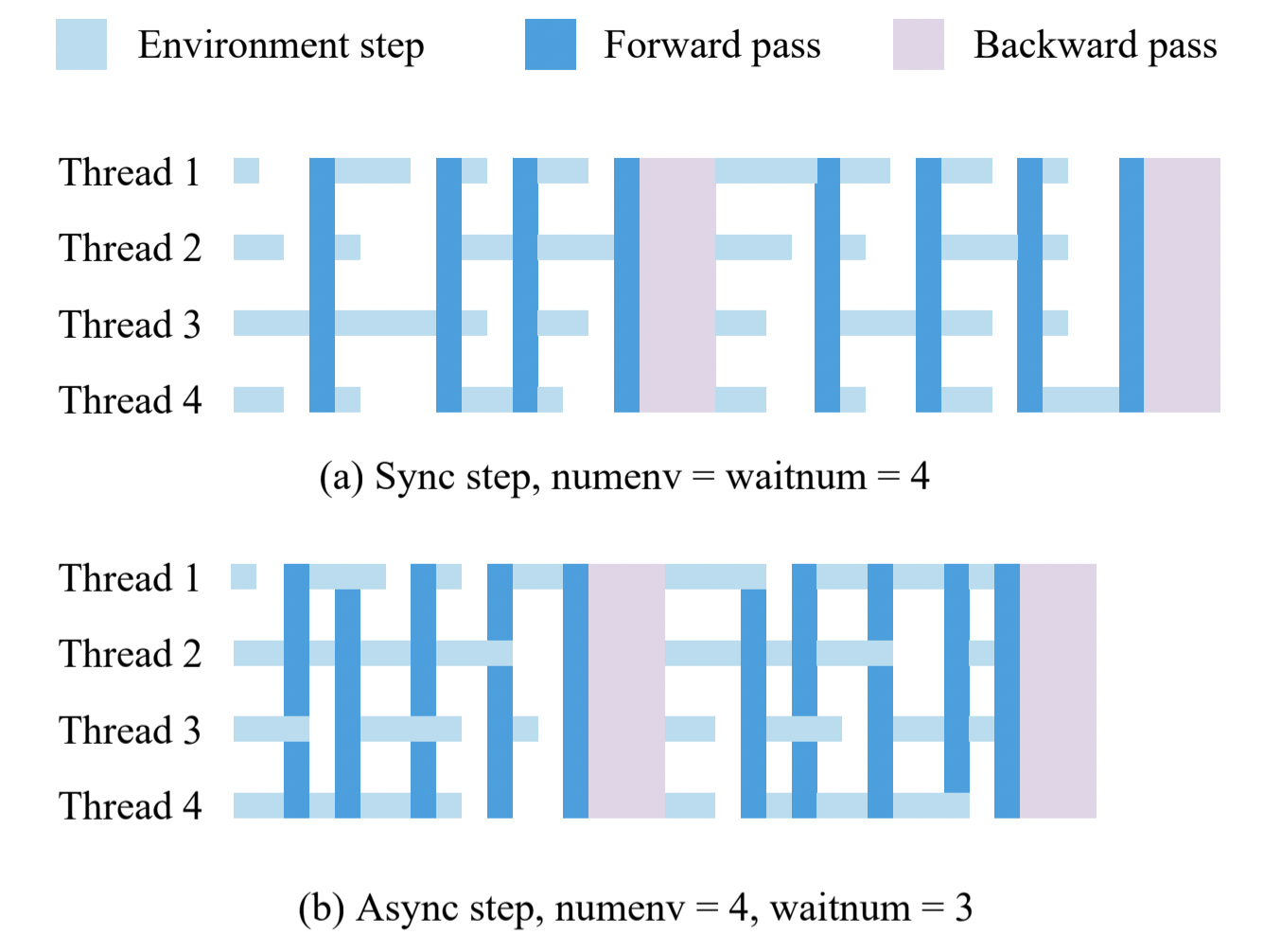
The synchronous step is a special case by using the above API:
batch_size == num_envs, id is always all envs’ id.
Auto Reset
EnvPool enables auto-reset by default. Let’s suppose an environment that has a
max_episode_steps = 3. When we call env.step(action) five consecutive
times, the following would happen:
the first call would trigger
env.reset()and return withdone = Falseandreward = 0, i.e., the action will be discarded;the second call would trigger
env.step(action)and elapsed step is 1;the third call would trigger
env.step(action)and elapsed step is 2;the fourth call would trigger
env.step(action)and elapsed step is 3. At this time it returnstruncated = True;the fifth call would trigger
env.reset()since the last episode has finished, and return withdone = Falseandreward = 0, i.e., the action will be discarded.
# |
User Call |
Actual |
Elapsed |
Misc |
|---|---|---|---|---|
1 |
env.step(a) |
env.reset() |
0 |
|
2 |
env.step(a) |
env.step(a) |
1 |
|
3 |
env.step(a) |
env.step(a) |
2 |
|
4 |
env.step(a) |
env.step(a) |
3 |
Hit max_episode_steps |
5 |
env.step(a) |
env.reset() |
0 |